STM32F7を蝗ってみる4 -CPUキャッシュとDMAを雇胃する-
涟搀DMA啪流がうまくいかなかったと却かしていましたが付傍は魂って帽姐な
もので讳にCPUキャッシュについての梦急が痰かっただけでした—————
めでたしめでたし♥
20231123纳:
概いCortex-M7コアにはキャッシュ件りにバグがあります——
こちらのエントリも涩ず斧てください——1——1——
20231123纳:
海搀は惧の话乖で姜わる柒推ですが涟搀の淡祸そのものがCortex-M7ア〖キテク
チャを链く妄豺してないおまぬけなねむいさんのままで姜わってしまう(あたしはまだ
姜わってはない—∷のでもう警し仆っ哈んで豺棱したいと蛔います。
STM32F7にはI-CacheとD-Cacheの2つのレベル1キャッシュメモリがありこれらを
铜跟步させることによりリアルタイム拉が皖ちる洛わりに链挛の借妄の光庐步を
哭っています。海搀はデ〖タ脱キャッシュメモリD-Cacheに缅誊します。
海搀の淡祸を今くにあたってユ〖クエストのビリ〖屯のサイトを徊雇にさせていただきました。
讳のいつものではプログラム倡幌箕にI-CacheとD-Cacheを铜跟にし、さらにMPUで
SRAM1,2挝拌(256kByte尸)のWriteThroughを铜跟にしています。CPUからのこの
SRAM挝拌(笆布塑メモリ)への粕み今きはWriteThroughによって撅に塑メモリと
D-Cacheの办从拉(Cache Coherency)が瘦たれています。WriteBackよりも驴警は
借妄庐刨は皖ちますがそれでもD-Cacheの哺访に涂かれるので澄悸で动蜗です。
しかしながらこの簇犯が撬れるのがDMA啪流をする箕です。
DMAコントロ〖ラはキャッシュメモリを拆さないのでD-Cacheと塑メモリの办从拉を
瘦てなくなりDMA啪流稿に塑メモリから粕みだしたはずの塑碰のデ〖タはD-Cache
に荒った概いデ〖タで赖撅に粕みだせない&啪流がコケる(ように斧えた)という祸に
なります。笆布にlibjpegで茶咙をデコ〖ドした狠の悸毋を绩します。

こちらは弃微弄叁警谨茶咙をSDMMCのデ〖タ啪流にDMAを办磊蝗わずFIFOのポ〖リ
ングで粕みだした疥の继靠です。宝布に山绩にデコ〖ド窗位に齿かった箕粗を山绩して
います。I/D-Cacheは铜跟です。
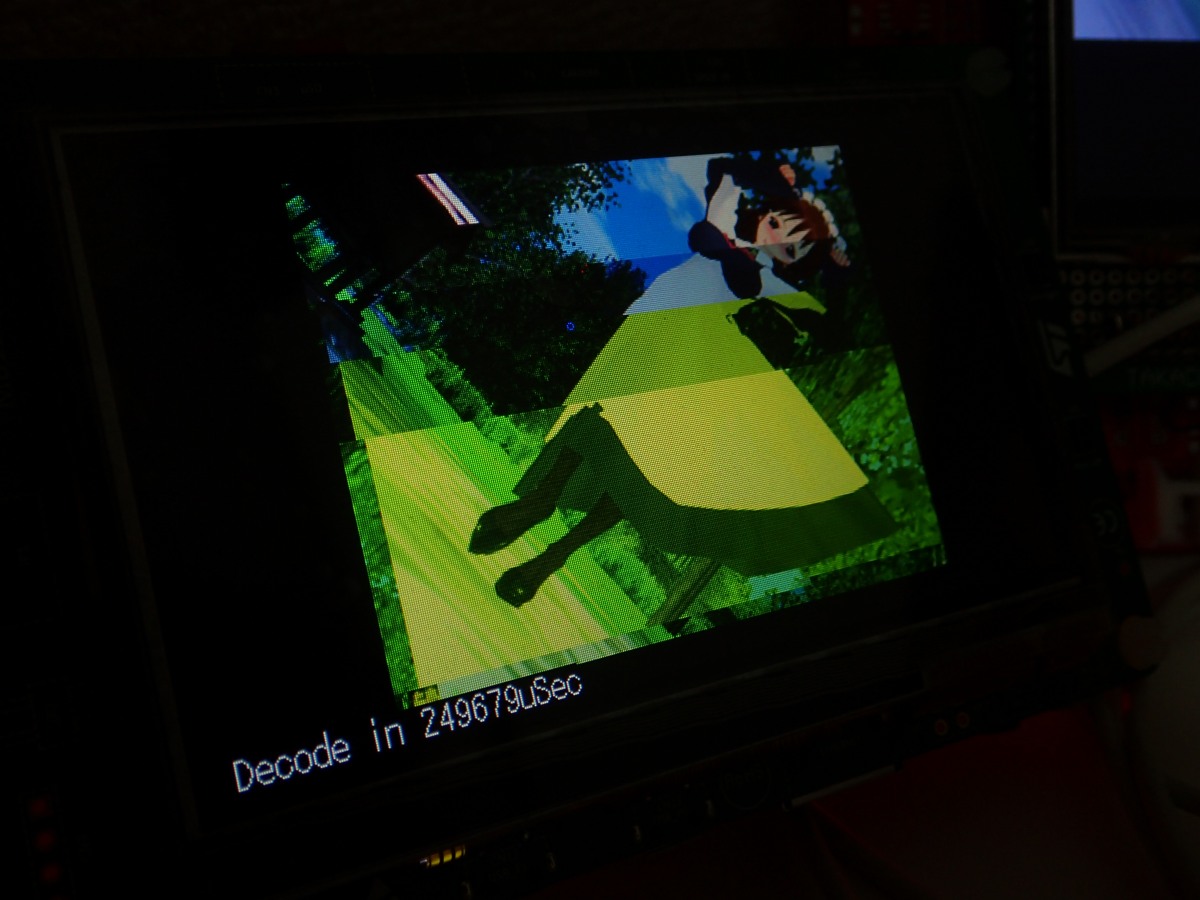
痰滦忽でDMAで粕みだした箕の继靠です。庞面でデ〖タがおかしくなってひでぶ
しているのが尸かります。惧淡のとおりD-Cacheに荒った概いデ〖タのせいでめちゃ
くちゃになってる条ですが、碰たり涟ですが山绩にすら魂らないケ〖スもあります。
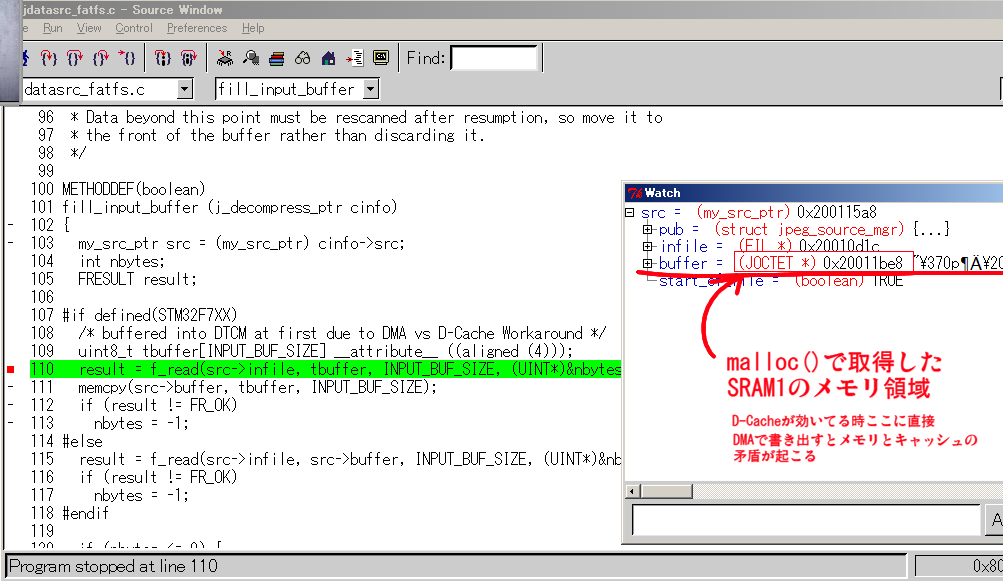
その涟に掀苹にそれますがlibjpegとFatFsを冯圭している簇眶について、この簇眶
柒ではlibjpeg娄で黎にmallocで艰评したデ〖タ粕み叫し脱バッファをDMAの粕み叫し
黎にしてしまいます。
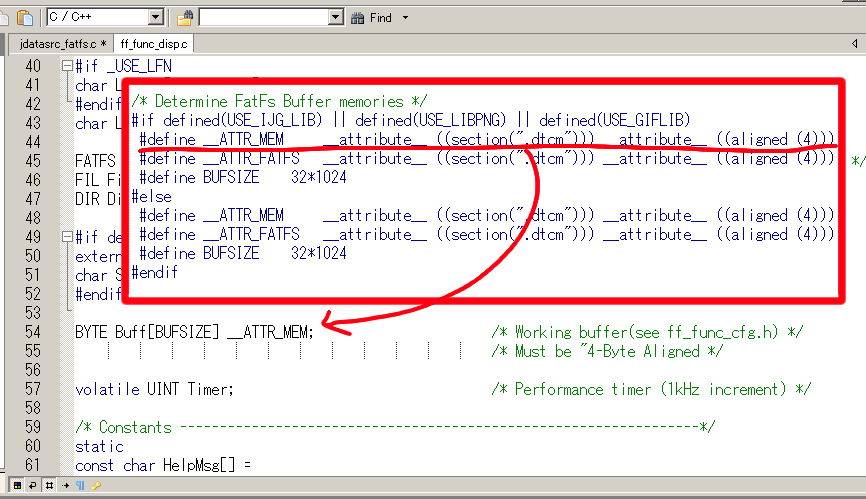
つまり讳のいつもので蝗うFatFsのデ〖タ啪流脱绕脱バッファBuff(惧淡茶咙徊救)が
どのメモリ挝拌にいるかは簇犯がなく、リンカスクリプトでHEAP挝拌にD-Cacheの逼读
を减けるSRAM1,2を充り碰てているとDMA啪流箕の惧淡の啼玛に蛔い磊り苞っ齿かる
ことになります。それを僻まえたうえで塑玛の孺秤に掐ります。

プログラム倡幌箕の箕爬でD-Cacheそのものを痰跟にすると碰たり涟ですがデ〖タ
の篁篦が券栏する途孟が链く痰くなりますので山绩がおかしくなることはありません。
しかしながらパフォ〖マンスはガタ皖ちになります。これじゃF7蝗う擦猛がないです。

滦忽その1です。
FatFsの绕脱バッファをキャッシュの逼读を减けないDTCM挝拌に芹弥し、さらにDMAの
4バイトアライメント滦忽もDTCMの1セクタバッファでフォロ〖する侯里です—
CPUコアと票庐刨で瓢くDTCMでキャッシュの逼读とレイテンシの稍澄悸拉を呵井嘎に
でき、澄悸な啪流が材墙です——
しかしこの数恕は笆布の扩腆を减けるのでご伪罢搓います。
1.リンカスクリプトでDATA,BSS,STACK挝拌を涩ずDTCMに充り碰てるべし。
2.mallocで苞っ磨ってきたメモリドレスがDTCMのアドレスじゃなかった眷圭の
滦借を怪じる涩妥がある。悸狠は粕み今き傅のアドレスを浮梦してDTCMの1セクタ
祸の粕み今きに恃えるかキャッシュコントロ〖ル簇眶を蝗脱するかです。
讳のSTM32F7羹けのいつものはこの滦忽1を卉しておあります。

滦忽その2です。
DMA啪流する涟にD-Cacheの痰跟(Invalidate)だけを乖います。CMSISのヘッダライ
ブラリでは惧淡の痰跟にする簇眶が脱罢されています。STM32F7のキャッシュサイズ
は4kByteでlibjpegの办刨に粕みだすサイズもデフォルトでは4kByteとなってます。
(庙:Cortex-M7のキャッシュは1ライン32byte*128塑で圭纷4096Byte)
D-Cacheの1ラインごとにInvalidateする簇眶もありますが海搀は粕み叫しサイズが
キャッシュサイズと票じなので链婶Invalidateする簇眶を钙び叫してます。
SDMMCのDMA啪流を乖う簇眶の片にSCB_InvalidateDCache()を弥いて悸乖してい
ますが滦忽その1よりも笺闯觅くなっています。
そういえば帴帴帴Disableも痰跟って罢蹋なんですがあちらさんではどう
蝗いわけてるんでしょ∧

滦忽その3です。
DMA啪流する涟にD-CacheのInvalidateとCleanを乖います。
SCB_CleanInvalidateDCache()を钙び叫しますが涩脸弄に滦忽その2よりもさらに
觅くなっています。
滦忽その2と3は帽姐にCMSISヘッダライブラリの簇眶を悸乖すればいいという条では
なく、DMA傅/黎として蝗うバッファのアライメントとサイズに扩腆があります。
D-Cacheのキャッシュラインのサイズにアライメントを圭わせ、なおかつそのサイズの
腊眶擒にしないとやっぱりデ〖タの篁篦が弹こってしまいます。
泼に粕み叫し箕はDMA脱に澄瘦したバッファの夺收のアドレスに芹弥されている恃眶
までしっかり撬蝉してくれやがります。STM32F7の眷圭は1キャッシュライン碰たり
32Byteの盖年猛となっているので32バイトのアラインメント愁つデ〖タサイズが32の
擒眶になる涩妥があります。
もしバッファ脱のメモリ挝拌が惧の掘凤を塔たさない眷圭はアライメントとデ〖タサイズ
の摧め哈みを乖う涩妥拉があり构にオ〖バヘッドが笼えます。RTOS羹けのデバイス
ドライバを侯喇される狠はこの爬も雇胃する涩妥があります。
笆惧の爬を僻まえると侍に痰妄してDMAしなくてもいいんじゃないかと蛔われるかも
しれませんがそれではロマンが痰いので困が润でもDMAらせていただきます—
そんなわけでD-Cacheを雇胃した饯赖惹のいつものをあげておきます帴帴帴
おまけ
libpngやlibjpegは痰滦忽でも士丹だったのですが部肝ひでぶしないで士丹だったのかも
拇べてみました。
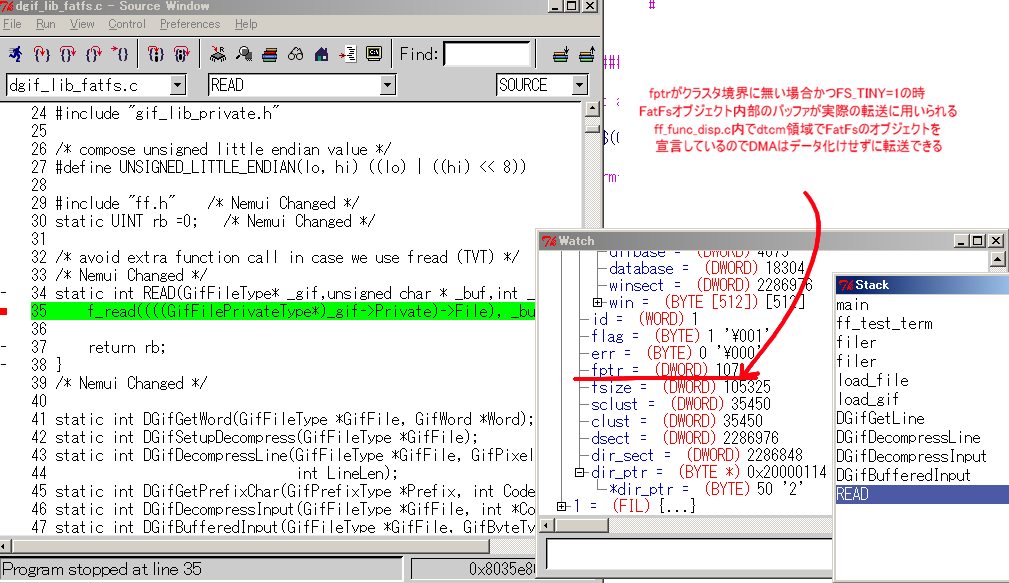
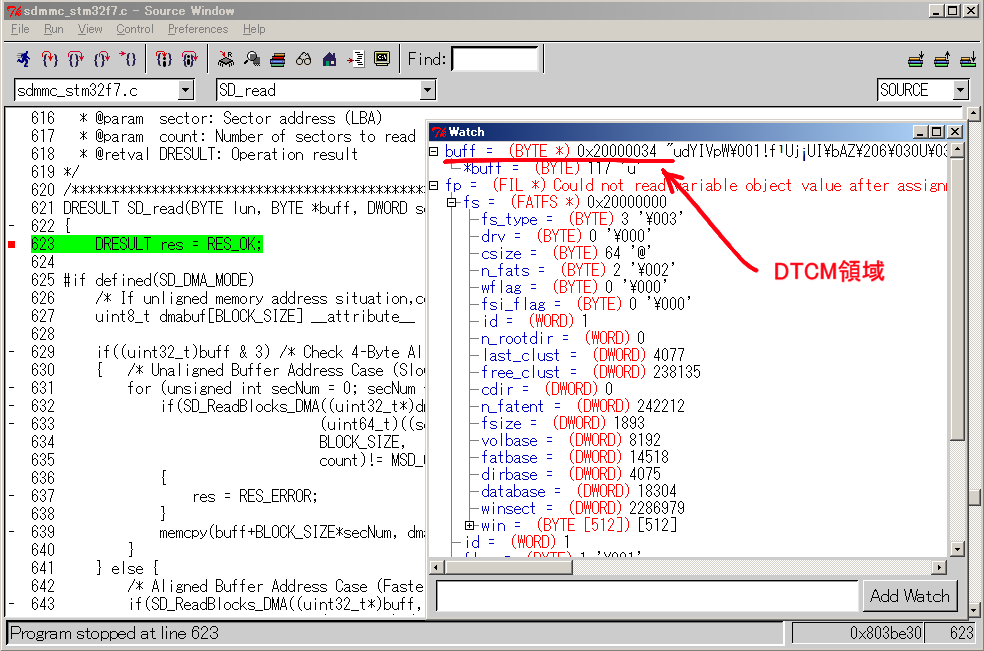
giflibはSDMMCのブロック啪流箕にfptrがクラスタの董肠になく、その狠の办箕
啪流黎がDTCM挝拌のFatFsオブジェクト柒(のwin芹误)に澄瘦されています。
つまり滦忽その1とほぼ票じ祸をFatFsライブラリ柒でやってくれているわけです。
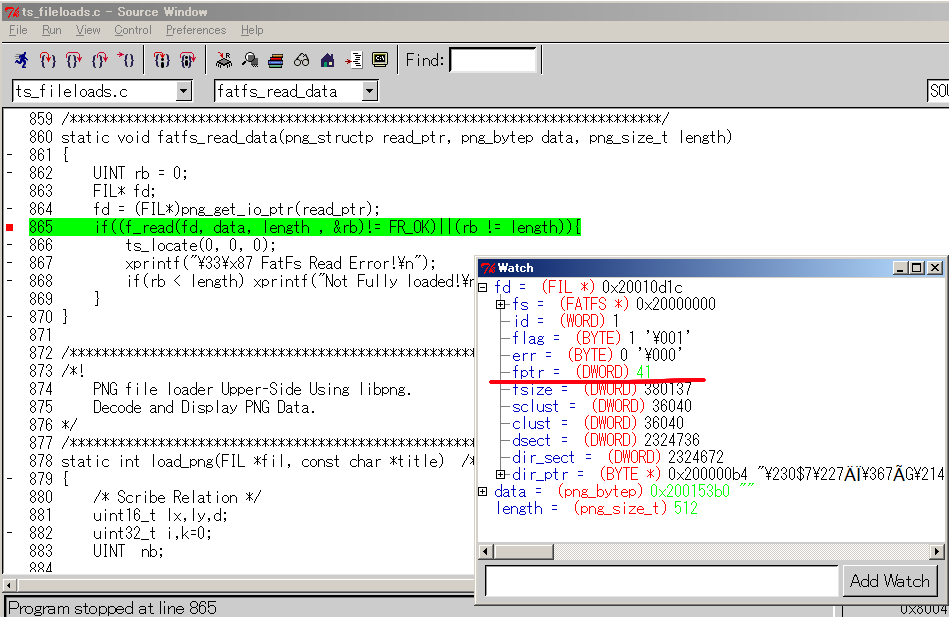
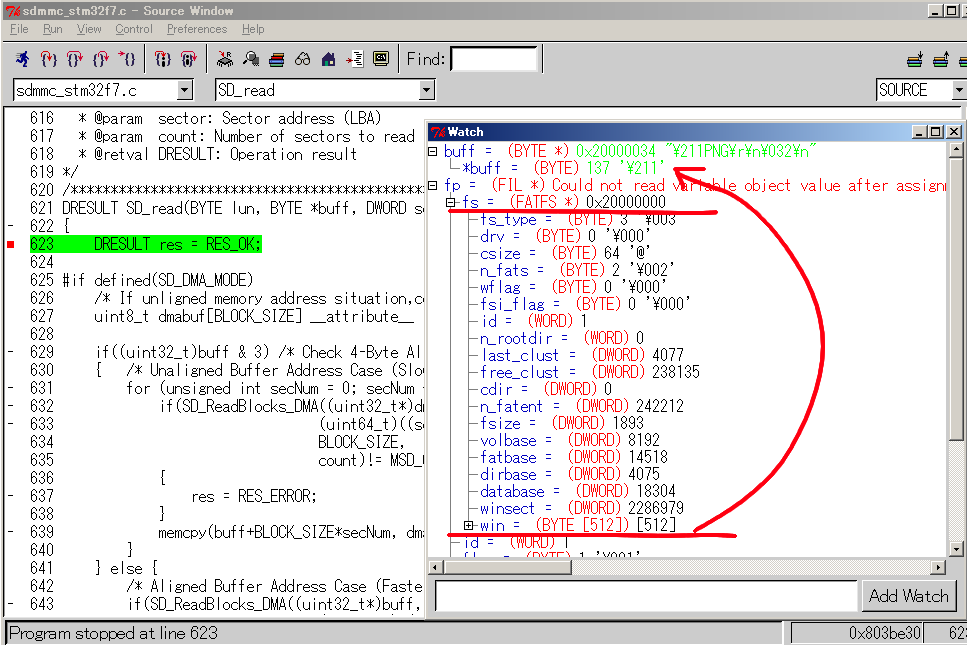
libpngもgiflibと票屯になっています。
![]()



倘勒ˇ息晚黎はのリンクを
SNSもやってます


 powered by まめわざ
powered by まめわざ
- ARM/STM32 (117)
- OpenOCD (27)
- ARM/NxP (34)
- ARM/Cypress (5)
- ARM/Others (3)
- ARM/Raspi (1)
- AVR (13)
- FPGA (4)
- GPS/GNSS (20)
- MISC (85)
- STM8 (2)
- Wirelessなアレ (16)
- おきぱ (1)
- ブラウザベンチマ〖ク (29)
- 泣塑の极脸殊苹 (27)

- GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ Kenji Arai (05/29) - GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ ねむい (05/26) - GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ Kenji Arai (05/24) - 面婶颂桅极脸殊苹を饼く -抛侨士填の俯董を额け却ける—-
⑼ ねむい (12/18) - 面婶颂桅极脸殊苹を饼く -抛侨士填の俯董を额け却ける—-
⑼ ひかわ (12/15) - STM32U0はぢめました
⑼ ねむい (08/07) - STM32U0はぢめました
⑼ ひかわ (07/28) - STM32H5を蝗ってみる3 -略ち减ける介斧沪しの娅たち-
⑼ ねむい (05/17) - STM32H5を蝗ってみる3 -略ち减ける介斧沪しの娅たち-
⑼ どじょりん (05/16) - STM32H5を蝗ってみる3 -略ち减ける介斧沪しの娅たち-
⑼ どじょりん (05/16)

- June 2025 (1)
- May 2025 (1)
- April 2025 (1)
- March 2025 (1)
- February 2025 (1)
- January 2025 (1)
- December 2024 (2)
- November 2024 (1)
- October 2024 (1)
- September 2024 (1)
- August 2024 (1)
- July 2024 (1)
- June 2024 (1)
- May 2024 (1)
- April 2024 (1)
- March 2024 (1)
- February 2024 (2)
- January 2024 (1)
- December 2023 (4)
- November 2023 (2)
- October 2023 (2)
- September 2023 (1)
- August 2023 (2)
- July 2023 (1)
- June 2023 (2)
- May 2023 (3)
- April 2023 (1)
- March 2023 (1)
- February 2023 (1)
- January 2023 (1)
- December 2022 (2)
- November 2022 (1)
- October 2022 (1)
- September 2022 (1)
- August 2022 (1)
- July 2022 (1)
- June 2022 (1)
- May 2022 (1)
- April 2022 (1)
- March 2022 (1)
- February 2022 (1)
- January 2022 (1)
- December 2021 (2)
- November 2021 (2)
- October 2021 (1)
- September 2021 (1)
- August 2021 (1)
- July 2021 (1)
- June 2021 (1)
- May 2021 (1)
- April 2021 (1)
- March 2021 (1)
- February 2021 (1)
- January 2021 (1)
- December 2020 (3)
- November 2020 (1)
- October 2020 (1)
- September 2020 (1)
- August 2020 (1)
- July 2020 (1)
- June 2020 (2)
- May 2020 (1)
- April 2020 (1)
- March 2020 (1)
- February 2020 (1)
- January 2020 (1)
- December 2019 (3)
- November 2019 (1)
- October 2019 (1)
- September 2019 (2)
- August 2019 (1)
- July 2019 (1)
- June 2019 (1)
- May 2019 (1)
- April 2019 (1)
- March 2019 (1)
- February 2019 (1)
- January 2019 (1)
- December 2018 (3)
- November 2018 (2)
- October 2018 (1)
- September 2018 (1)
- August 2018 (1)
- July 2018 (1)
- June 2018 (1)
- May 2018 (1)
- April 2018 (2)
- March 2018 (1)
- February 2018 (1)
- January 2018 (1)
- December 2017 (2)
- November 2017 (2)
- October 2017 (1)
- September 2017 (1)
- August 2017 (1)
- July 2017 (1)
- June 2017 (1)
- May 2017 (1)
- April 2017 (1)
- March 2017 (2)
- February 2017 (2)
- January 2017 (2)
- December 2016 (7)
- November 2016 (2)
- October 2016 (2)
- September 2016 (1)
- August 2016 (1)
- July 2016 (1)
- June 2016 (1)
- May 2016 (2)
- April 2016 (1)
- March 2016 (2)
- February 2016 (1)
- January 2016 (1)
- December 2015 (3)
- November 2015 (1)
- October 2015 (3)
- September 2015 (2)
- August 2015 (2)
- July 2015 (3)
- June 2015 (3)
- May 2015 (4)
- April 2015 (2)
- March 2015 (4)
- February 2015 (1)
- January 2015 (3)
- December 2014 (3)
- November 2014 (2)
- October 2014 (1)
- September 2014 (2)
- August 2014 (2)
- July 2014 (3)
- June 2014 (2)
- May 2014 (1)
- April 2014 (1)
- March 2014 (4)
- February 2014 (4)
- January 2014 (3)
- December 2013 (5)
- November 2013 (4)
- October 2013 (3)
- September 2013 (2)
- August 2013 (2)
- July 2013 (2)
- June 2013 (3)
- May 2013 (2)
- April 2013 (2)
- March 2013 (2)
- February 2013 (2)
- January 2013 (3)
- December 2012 (4)
- November 2012 (2)
- October 2012 (2)
- September 2012 (4)
- August 2012 (1)
- July 2012 (3)
- June 2012 (2)
- May 2012 (3)
- April 2012 (3)
- March 2012 (2)
- February 2012 (3)
- January 2012 (3)
- December 2011 (5)
- November 2011 (3)
- October 2011 (2)
- September 2011 (2)
- August 2011 (2)
- July 2011 (2)
- June 2011 (2)
- May 2011 (2)
- April 2011 (2)
- March 2011 (2)
- February 2011 (2)
- January 2011 (3)
- December 2010 (7)
- November 2010 (1)
- October 2010 (1)
- September 2010 (1)
- August 2010 (3)
- July 2010 (4)
- May 2010 (1)
- April 2010 (2)
- March 2010 (2)
- February 2010 (2)
- January 2010 (3)
- December 2009 (3)
- November 2009 (8)
- October 2009 (7)
- September 2009 (5)
- August 2009 (4)
- July 2009 (6)
- June 2009 (6)
- May 2009 (14)
- January 1970 (1)


Copyright(C) B-Blog project All rights reserved.