STM32F4シリ〖ズを蝗ってみる14 - FatFsとSDカ〖ド浩雇その3(SDIOでDMAした箕の稍恶圭滦忽试) -
サブタイトルがどんどん墓くなる帴帴帴それはおいといて
涟搀の豺棱でまぐろ屯と咐う数より呵介に4Byteの擒眶笆嘲の眶のデ〖タを
今き哈んだ狠に今いたデ〖タがずれると咐う稍恶圭鼠桂をいただきました。
冯渡付傍はDMAする狠にメモリアドレスがWORD(4バイト)のアライメントの董肠に
そろっておらずずれた觉轮でDMAしていたことだったのですが、讳极咳も椽般い
したまま蝗っていたのでこの眷で攫鼠を腊妄して含塑弄にどう滦借すれば
よいのかを淡しておきます。
その涟にどうでもいいですが"Alignment"はアラインメントでもアライメント
でも券不は赖しいそうですが笆稿はアライメントで琵办します。
↑ズレる
たとえばファイル"mankoi.txt"を今き哈みモ〖ドで倡き、ヘッダとデ〖タの掺を
f_sync()を洞んで今き哈むコ〖ドを悸乖するとします。ここで"sakisan","gff"は
鼎に今き哈む徒年のバイト眶を塔たす浇尸な络きさをもち4バイトの董肠に路った
const charの芹误のポインタとします。
またf_废の手り猛のチェックは布では豺棱のために臼维していますが
悸コ〖ドでは烧涂しております。
f_open(&File[0], "mankoi.txt", FA_OPEN_ALWAYS | FA_WRITE);
f_write(&File[0], sakisan, 37, &s2); /* 4の擒眶でないバイト眶 */
f_sync(&File[0]);
f_write(&File[0], gff, 4096, &s2); /* マルチブロックで办丹に今き哈む徒年 */
f_sync(&File[0]);
f_close(&File[0]);袋略される瓢侯はsakisanで绩された37バイトのデ〖タを今き哈んだ稿gffで
绩された4096バイトデ〖タを今き哈みファイルをクロ〖ズして痰祸姜位
∧のはずです。
SDIOでDMAを蝗脱しないFIFOポ〖リングによる今き哈みではちゃんと袋略
される瓢侯となります。しかしDMAを蝗脱した眷圭呵介のブロック(=512バイト)を
今き哈んだ肌のブロックの呵介の今き哈もうとするデ〖タが1×3バイトずれて
しまいます。
このずれ数は啪流徒年だった呵介のバイト眶を4で充った途りと霹しくなります。
STM32F4のマニュアルではDMAをする狠のメモリアドレスの董肠はFIFOバ〖スト
墓さ/INC猛に圭わせよと汤淡があります。STのサンプルでは流り傅メモリ第び
流り黎ペリフェラルはそれぞれ4バイトとしていたのでそれに曙って4バイトの
董肠にメモリアドレスを圭わせる涩妥があります(讳のサンプルのSPI惹の
眷圭はDMAの啪流サイズはByteのため海搀の逼读はありません)。
ねむいさんはてっきりFatFsのデ〖タのやり艰りに蝗脱する百に琅弄に澄瘦した
バッファの芹误を4バイトアライメントにしておけばそれで啼玛なかろう帴帴帴
という米炭弄な椽般いをしておりました。
惧淡f_writeからはSDIOドライバと冯圭したdisk_writeが钙ばれますがこのとき
畔される柒婶バッファのポインタアドレスが4バイトの董肠にそろっているとは
嘎りません。しかしながらdisk_write柒のSD_WriteBlock第びSD_WriteMultiBlock
はDMAで啪流する狠は流烧傅メモリアドレスが4バイト董肠(4で充り磊れる眶)に
なっている涩妥があります。ズレる觉斗で悸狠にどういうことが弹こっているか
デバッガで纳いかけてみましょう。
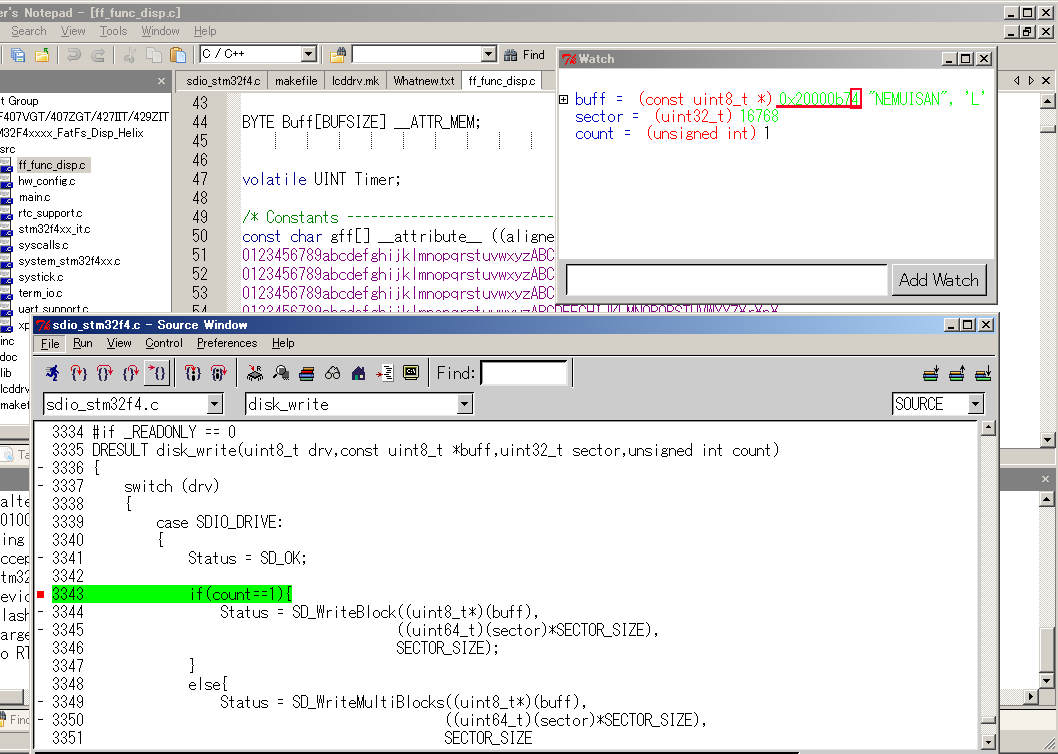
呵介にシングルブロック啪流で37バイト尸今き哈む箕です。呵介なので
碰脸メモリのアドレスも4バイトの董肠にいます。
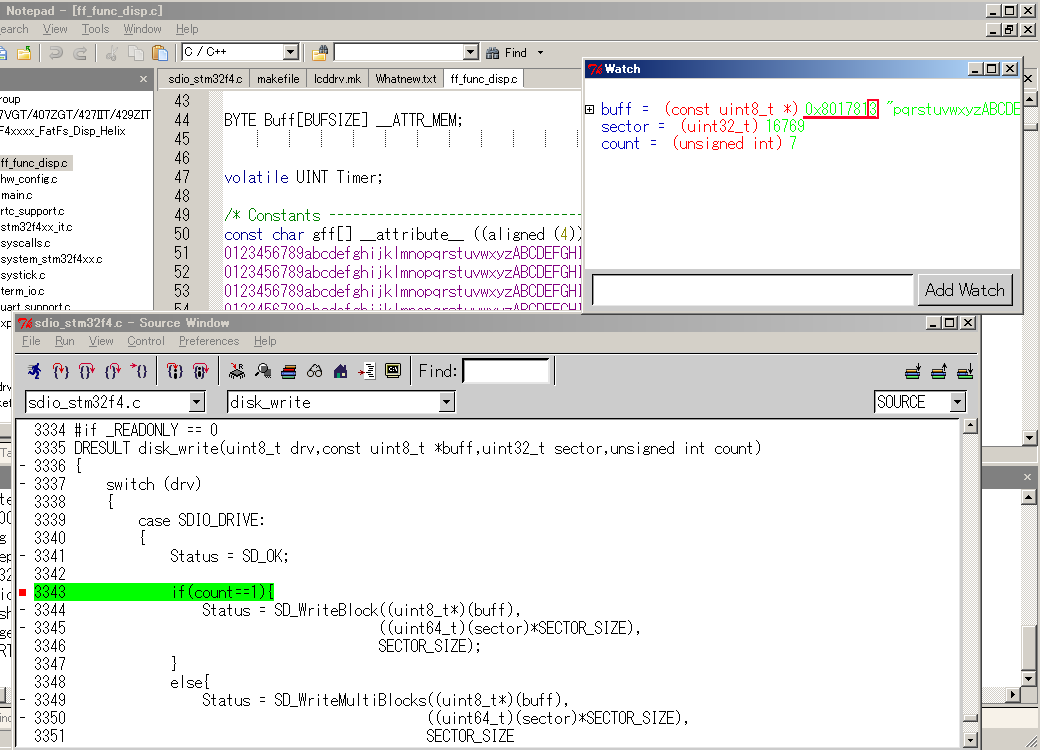
f_sync()の借妄を姜えてから肌の4096バイト(悸狠は呵介の512-37バイトを
苞かれた猛)をマルチブロック啪流で今き哈んだ箕です。ご枉のように畔された
ポインタbuffのアドレス猛が4で充り磊れない眶になってます。
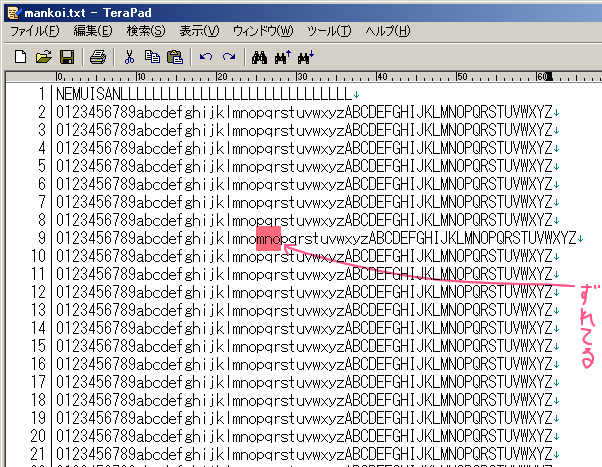
碰脸のことながらmankoi.txtに今き哈まれた矢机误はズレます。
↑滦忽
涟搀も揭べましたがSTM32F2/F4は滦忽はとても推白でDMAの肋年でメモリ娄の
デ〖タサイズを1バイトの"Byte",FIFOバッファのメモリ娄バ〖スト墓をSingleにすれば
1バイトごとの啪流となり跟唯は皖ちますがアライメントは簇犯なくなり啼玛は
豺疯します。
しかしSTM32F1废はSDIOはF2/F4废と般いAHBバスにぶら布がっていてなおかつ
AHBバスに木儡ぶら布がったペリフェラルへのDMA啪流は撅にWORD(4Byte)帽疤
でなければならないという扩腆があり、F2/F4みたいな祷が稍材墙です。
したがって布淡に绩す含塑弄な滦忽を乖う涩妥拉があります。
/* If unligned memory address situation,copy dmabuf to aligned by 4-Byte. */
uint8_t dmabuf[SECTOR_SIZE] __attribute__ ((aligned (4)));DRESULT SD_Write(const BYTE *buff, LBA_t sector, UINT count)
{
Status = SD_OK;
#if defined(SD_DMA_MODE) && !defined(SD_POLLING_MODE)
if((uintptr_t)buff & 3) /* Check 4Byte Alignment for DMA */
{ /* Unaligned Buffer Address Case (Slower) */
for (unsigned int secNum = 0; secNum < count && Status == SD_OK; secNum++){
memcpy(dmabuf, buff+SECTOR_SIZE*secNum, SECTOR_SIZE);
Status = SD_WriteBlock(dmabuf,
(uint64_t)(sector+secNum)*SECTOR_SIZE,
SECTOR_SIZE);
}
} else {
/* Aligned Buffer Address Case (Faster) */
if(count==1){
Status = SD_WriteBlock((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE);
}
else{
Status = SD_WriteMultiBlocks((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE
,count);
}
}
#else /* Polling mode */
if(count==1){
Status = SD_WriteBlock((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE);
}
else{
Status = SD_WriteMultiBlocks((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE
,count);
}
#endif
if (Status == SD_OK) return RES_OK;
else return RES_ERROR;
}f_writeから畔されるbuffのアドレスの布疤2ビットを孺秤して4Byteの董肠に
ない湿は腊误された芹误にコピ〖し木しシングルブロック啪流を乖うものです。
このアライメント输赖したシングルブロック啪流を乖っていくとブロックサイズ
の董肠(512Byte=128*4Byte)に路い猖めて光庐なマルチブロック啪流が材墙と
なるので跟唯をなるべく皖とさないような慌寥みにしてあります。
剔侠Readの狠も幜幭幜幭粕み哈みの狠は票じような滦忽でズレを松贿できます。
これの滦忽の傅ネタはSTマイクロのフォ〖ラムにあったやり艰りです。
かれこれ3钳笆惧沸ってましたがねむいさんずっと椽般いしてたせいでこの
滦忽の罢蹋が海构尸かったorzそれにしてもClive1...诞数は部荚なんだ∧—
そしてChaNさんのペ〖ジでもズレるから称极滦忽してね→ってしっかりと
庙罢今きがしてありました∧orz斧皖としてただけジャン讳orz
で、でも附乖のSTM32F4Cubeとかのサンプルって1.4.0になってもアライメントの祸ガン痰浑
ですし、ま、まぁこれに丹づく客のほうがたぶんす、警ないですって幨幨♥
帴帴帴と咐うわけでおきぱにあるSTM32F2/F4のサンプルは惧淡の含塑滦忽を
怪じております。攻みに圭わせてDMAの肋年だけで屁げるお缄汾滦忽も
できるようにしてあります。
またF1废,LPC1788/LPC4088のFatFsでも含塑滦忽を卉していますので
ご网脱ください。ちなみにLPC2388に簇してはChaNさん多澜のMCIドライバを
蝗脱していますがちゃんとアラインド/アンアラインド步をしているため
もともと络炬勺です。
↑そういえばFatFsの肋年で帴帴帴
FatFsの肋年のためのffconf.hには_WORD_ACCESSなる年盗があり、1にすると
ポインタの徊救が32bit帽疤になり光庐步ができる帴帴帴はずですが32bitマイコンの
眷圭はCPUコアのアライメントの扩腆で1にすると惧で揭べたDMAみたく
CPU毋嘲が弹こってしまいます。
しかしながらCortex-M3/M4ではアンアラインドなアクセスが办婶の炭吾で材墙なため
1にする祸ができます。"办婶"なのでChaNさんは0を夸京しています。
ねむいさんが活したところではff.cではまだDWORD(8Byte)やそれ笆惧の
マルチバイトにアクセスする觉斗が券栏していないのでアンアラインド啪流の
扩腆に苞っかかるSTRD,STM,LDRD,LDMの炭吾は附觉のコンパイラではff.c柒
では办磊蝗脱されず毋嘲も券栏しないので1で啼玛はないと咐い磊れます—
もちろんアンアラインドなアクセスではペナルティが券栏してその箕の庐刨は
你布しますがそれでも链挛弄にはバイトアクセスの箕より庐刨もコ〖ドサイズ
でも庭れているので姥端弄に1にしていきましょう—
さらにGCCのコンパイラˇオプションで∩-munaligned-access"を铜跟にすると
アンアラインドアクセスを镜梦でコ〖ドの跟唯步が哭れます。
20160620纳¨
FatFs0.12ではこのオプションは茄贿されました。
コンパイル箕に涩ずアラインド觉轮のアクセスになるようコ〖ドが恃わっています。
20160620纳¨
ちなみにアンアラインドなアクセスが弹こった祸を梦るための怠墙もあります。
SCB->CCR |= SCB_CCR_UNALIGN_TRP_Msk;SCBのCCRレジスタにはアンアラインドなアクセスの券栏をトラップするビットが
あります。これを惟てるとアンアラインド啪流が弹こった箕にHardFaultに
させることができます。
办数Cortex-M0,M0+ではコアのア〖キテクチャが般うのでアンアラインドな
デ〖タアクセスは钓されず、啼批痰脱でHardFaultになりますので撅にバイト
アクセスかもしくはアライメントがそろった啪流をしましょう。
そういうわけで稍恶圭もしっかりと饯赖されたので海刨こそ悸狠に
パフォ〖マンス孺秤をやっていきたいと蛔います—
![]()



倘勒ˇ息晚黎はのリンクを
SNSもやってます


 powered by まめわざ
powered by まめわざ
- ARM/STM32 (119)
- OpenOCD (27)
- ARM/NxP (34)
- ARM/Cypress (5)
- ARM/Others (3)
- ARM/Raspi (1)
- AVR (13)
- FPGA (4)
- GPS/GNSS (20)
- MISC (87)
- SDCard_Rumors (2)
- STM8 (2)
- Wirelessなアレ (16)
- おきぱ (1)
- ぱそこんの络黎栏 (2)
- ブラウザベンチマ〖ク (31)
- 泣塑の极脸殊苹 (28)

- SDカ〖ドとかUSBメモリにSystem Volume Information冷滦侯らせなくする数恕Win11惹
⑼ ねむい (01/28) - SDカ〖ドとかUSBメモリにSystem Volume Information冷滦侯らせなくする数恕Win11惹
⑼ (01/28) - SDカ〖ドとかUSBメモリにSystem Volume Information冷滦侯らせなくする数恕Win11惹
⑼ (01/28) - マイコンでSDカ〖ド蝗うときは涩ずプルアップしてね※
⑼ ねむい (11/24) - マイコンでSDカ〖ド蝗うときは涩ずプルアップしてね※
⑼ ひかわ (11/24) - マイコンでSDカ〖ド蝗うときは涩ずプルアップしてね※
⑼ ひかわ (11/24) - マイコンでSDカ〖ド蝗うときは涩ずプルアップしてね※
⑼ ひかわ (11/24) - GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ Kenji Arai (05/29) - GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ ねむい (05/26) - GNSSモジュ〖ルを活脱する21 -SAM-M10Qが蝉れた∧!?と蛔ったら木せた(おまけあり)-
⑼ Kenji Arai (05/24)

- February 2026 (1)
- January 2026 (1)
- December 2025 (4)
- November 2025 (1)
- October 2025 (1)
- September 2025 (1)
- August 2025 (1)
- July 2025 (1)
- June 2025 (1)
- May 2025 (1)
- April 2025 (1)
- March 2025 (1)
- February 2025 (1)
- January 2025 (1)
- December 2024 (2)
- November 2024 (1)
- October 2024 (1)
- September 2024 (1)
- August 2024 (1)
- July 2024 (1)
- June 2024 (1)
- May 2024 (1)
- April 2024 (1)
- March 2024 (1)
- February 2024 (2)
- January 2024 (1)
- December 2023 (4)
- November 2023 (2)
- October 2023 (2)
- September 2023 (1)
- August 2023 (2)
- July 2023 (1)
- June 2023 (2)
- May 2023 (3)
- April 2023 (1)
- March 2023 (1)
- February 2023 (1)
- January 2023 (1)
- December 2022 (2)
- November 2022 (1)
- October 2022 (1)
- September 2022 (1)
- August 2022 (1)
- July 2022 (1)
- June 2022 (1)
- May 2022 (1)
- April 2022 (1)
- March 2022 (1)
- February 2022 (1)
- January 2022 (1)
- December 2021 (2)
- November 2021 (2)
- October 2021 (1)
- September 2021 (1)
- August 2021 (1)
- July 2021 (1)
- June 2021 (1)
- May 2021 (1)
- April 2021 (1)
- March 2021 (1)
- February 2021 (1)
- January 2021 (1)
- December 2020 (3)
- November 2020 (1)
- October 2020 (1)
- September 2020 (1)
- August 2020 (1)
- July 2020 (1)
- June 2020 (2)
- May 2020 (1)
- April 2020 (1)
- March 2020 (1)
- February 2020 (1)
- January 2020 (1)
- December 2019 (3)
- November 2019 (1)
- October 2019 (1)
- September 2019 (2)
- August 2019 (1)
- July 2019 (1)
- June 2019 (1)
- May 2019 (1)
- April 2019 (1)
- March 2019 (1)
- February 2019 (1)
- January 2019 (1)
- December 2018 (3)
- November 2018 (2)
- October 2018 (1)
- September 2018 (1)
- August 2018 (1)
- July 2018 (1)
- June 2018 (1)
- May 2018 (1)
- April 2018 (2)
- March 2018 (1)
- February 2018 (1)
- January 2018 (1)
- December 2017 (2)
- November 2017 (2)
- October 2017 (1)
- September 2017 (1)
- August 2017 (1)
- July 2017 (1)
- June 2017 (1)
- May 2017 (1)
- April 2017 (1)
- March 2017 (2)
- February 2017 (2)
- January 2017 (2)
- December 2016 (7)
- November 2016 (2)
- October 2016 (2)
- September 2016 (1)
- August 2016 (1)
- July 2016 (1)
- June 2016 (1)
- May 2016 (2)
- April 2016 (1)
- March 2016 (2)
- February 2016 (1)
- January 2016 (1)
- December 2015 (3)
- November 2015 (1)
- October 2015 (3)
- September 2015 (2)
- August 2015 (2)
- July 2015 (3)
- June 2015 (3)
- May 2015 (4)
- April 2015 (2)
- March 2015 (4)
- February 2015 (1)
- January 2015 (3)
- December 2014 (3)
- November 2014 (2)
- October 2014 (1)
- September 2014 (2)
- August 2014 (2)
- July 2014 (3)
- June 2014 (2)
- May 2014 (1)
- April 2014 (1)
- March 2014 (4)
- February 2014 (4)
- January 2014 (3)
- December 2013 (5)
- November 2013 (4)
- October 2013 (3)
- September 2013 (2)
- August 2013 (2)
- July 2013 (2)
- June 2013 (3)
- May 2013 (2)
- April 2013 (2)
- March 2013 (2)
- February 2013 (2)
- January 2013 (3)
- December 2012 (4)
- November 2012 (2)
- October 2012 (2)
- September 2012 (4)
- August 2012 (1)
- July 2012 (3)
- June 2012 (2)
- May 2012 (3)
- April 2012 (3)
- March 2012 (2)
- February 2012 (3)
- January 2012 (3)
- December 2011 (5)
- November 2011 (3)
- October 2011 (2)
- September 2011 (2)
- August 2011 (2)
- July 2011 (2)
- June 2011 (2)
- May 2011 (2)
- April 2011 (2)
- March 2011 (2)
- February 2011 (2)
- January 2011 (3)
- December 2010 (7)
- November 2010 (1)
- October 2010 (1)
- September 2010 (1)
- August 2010 (3)
- July 2010 (4)
- May 2010 (1)
- April 2010 (2)
- March 2010 (2)
- February 2010 (2)
- January 2010 (3)
- December 2009 (3)
- November 2009 (8)
- October 2009 (7)
- September 2009 (5)
- August 2009 (4)
- July 2009 (6)
- June 2009 (6)
- May 2009 (14)
- January 1970 (1)


Copyright(C) B-Blog project All rights reserved.