STM32F4シリーズを使ってみる14 - FatFsとSDカード再考その3(SDIOでDMAした時の不具合対策編) -
サブタイトルがどんどん長くなる・・・それはおいといて
前回の解説でまぐろ様と言う方より最初に4Byteの倍数以外の数のデータを
書き込んだ際に書いたデータがずれると言う不具合報告をいただきました。
結局原因はDMAする際にメモリアドレスがWORD(4バイト)のアライメントの境界に
そろっておらずずれた状態でDMAしていたことだったのですが、私自身も勘違い
したまま使っていたのでこの場で情報を整理して根本的にどう対処すれば
よいのかを記しておきます。
その前にどうでもいいですが"Alignment"はアラインメントでもアライメント
でも発音は正しいそうですが以後はアライメントで統一します。
●ズレる
たとえばファイル"mankoi.txt"を書き込みモードで開き、ヘッダとデータの塊を
f_sync()を挟んで書き込むコードを実行するとします。ここで"sakisan","gff"は
共に書き込む予定のバイト数を満たす十分な大きさをもち4バイトの境界に揃った
const charの配列のポインタとします。
またf_系の返り値のチェックは下では解説のために省略していますが
実コードでは付与しております。
f_open(&File[0], "mankoi.txt", FA_OPEN_ALWAYS | FA_WRITE);
f_write(&File[0], sakisan, 37, &s2); /* 4の倍数でないバイト数 */
f_sync(&File[0]);
f_write(&File[0], gff, 4096, &s2); /* マルチブロックで一気に書き込む予定 */
f_sync(&File[0]);
f_close(&File[0]);期待される動作はsakisanで示された37バイトのデータを書き込んだ後gffで
示された4096バイトデータを書き込みファイルをクローズして無事終了
…のはずです。
SDIOでDMAを使用しないFIFOポーリングによる書き込みではちゃんと期待
される動作となります。しかしDMAを使用した場合最初のブロック(=512バイト)を
書き込んだ次のブロックの最初の書き込もうとするデータが1〜3バイトずれて
しまいます。
このずれ方は転送予定だった最初のバイト数を4で割った余りと等しくなります。
STM32F4のマニュアルではDMAをする際のメモリアドレスの境界はFIFOバースト
長さ/INC値に合わせよと明記があります。STのサンプルでは送り元メモリ及び
送り先ペリフェラルはそれぞれ4バイトとしていたのでそれに倣って4バイトの
境界にメモリアドレスを合わせる必要があります(私のサンプルのSPI版の
場合はDMAの転送サイズはByteのため今回の影響はありません)。
ねむいさんはてっきりFatFsのデータのやり取りに使用する為に静的に確保した
バッファの配列を4バイトアライメントにしておけばそれで問題なかろう・・・
という致命的な勘違いをしておりました。
上記f_writeからはSDIOドライバと結合したdisk_writeが呼ばれますがこのとき
渡される内部バッファのポインタアドレスが4バイトの境界にそろっているとは
限りません。しかしながらdisk_write内のSD_WriteBlock及びSD_WriteMultiBlock
はDMAで転送する際は送付元メモリアドレスが4バイト境界(4で割り切れる数)に
なっている必要があります。ズレる状況で実際にどういうことが起こっているか
デバッガで追いかけてみましょう。
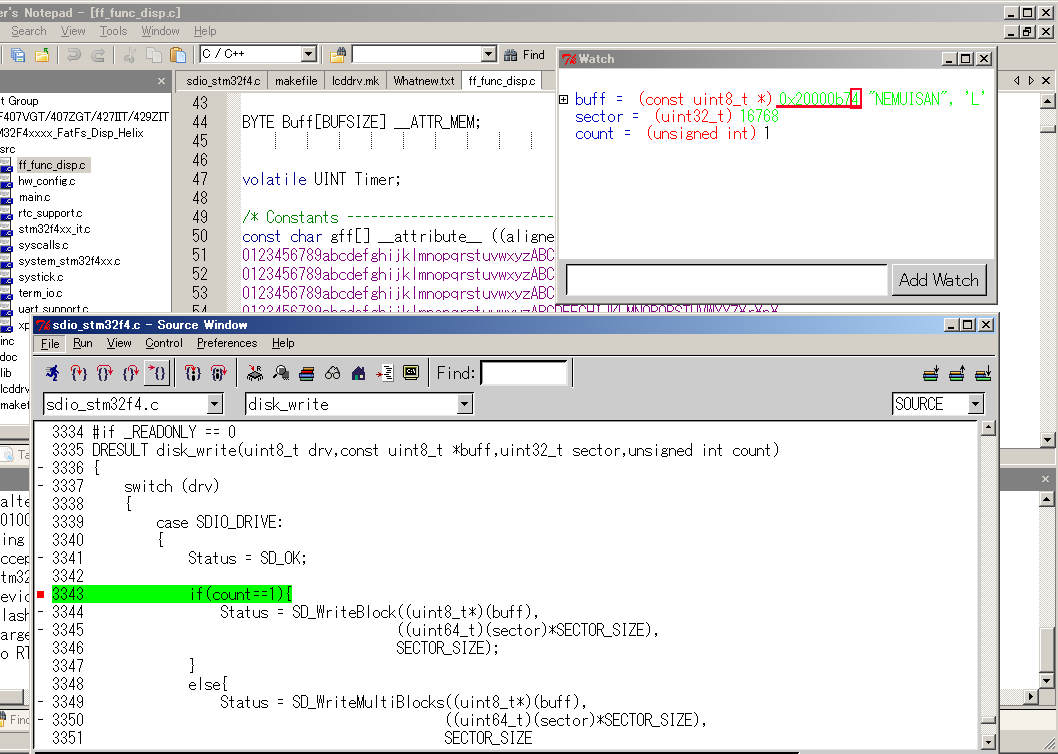
最初にシングルブロック転送で37バイト分書き込む時です。最初なので
当然メモリのアドレスも4バイトの境界にいます。
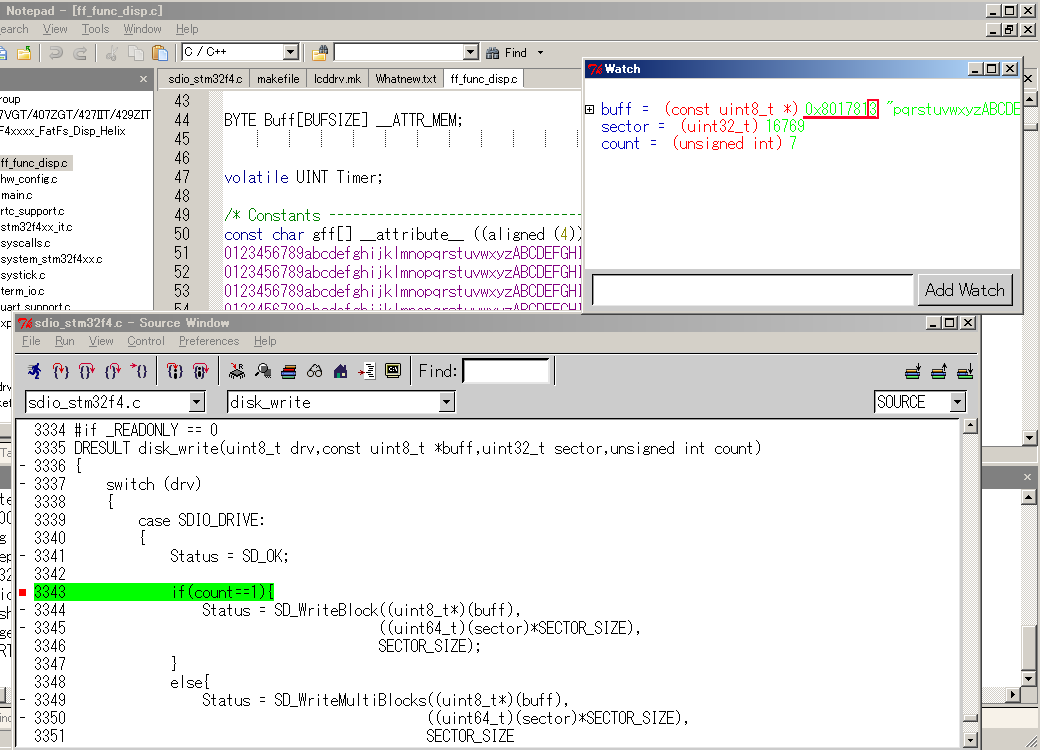
f_sync()の処理を終えてから次の4096バイト(実際は最初の512-37バイトを
引かれた値)をマルチブロック転送で書き込んだ時です。ご覧のように渡された
ポインタbuffのアドレス値が4で割り切れない数になってます。
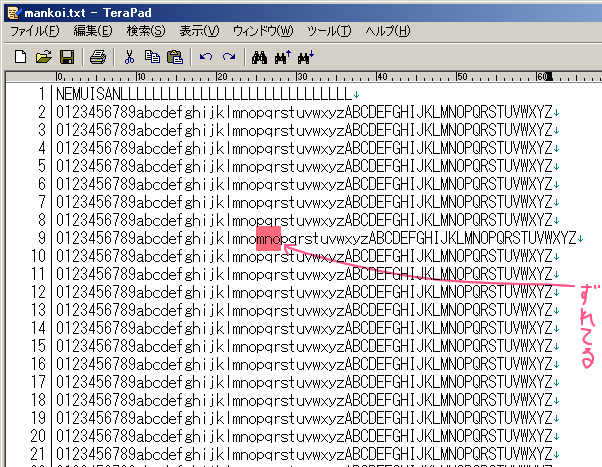
当然のことながらmankoi.txtに書き込まれた文字列はズレます。
●対策
前回も述べましたがSTM32F2/F4は対策はとても容易でDMAの設定でメモリ側の
データサイズを1バイトの"Byte",FIFOバッファのメモリ側バースト長をSingleにすれば
1バイトごとの転送となり効率は落ちますがアライメントは関係なくなり問題は
解決します。
しかしSTM32F1系はSDIOはF2/F4系と違いAHBバスにぶら下がっていてなおかつ
AHBバスに直接ぶら下がったペリフェラルへのDMA転送は常にWORD(4Byte)単位
でなければならないという制約があり、F2/F4みたいな技が不可能です。
したがって下記に示す根本的な対策を行う必要性があります。
/* If unligned memory address situation,copy dmabuf to aligned by 4-Byte. */
uint8_t dmabuf[SECTOR_SIZE] __attribute__ ((aligned (4)));DRESULT SD_Write(const BYTE *buff, LBA_t sector, UINT count)
{
Status = SD_OK;
#if defined(SD_DMA_MODE) && !defined(SD_POLLING_MODE)
if((uintptr_t)buff & 3) /* Check 4Byte Alignment for DMA */
{ /* Unaligned Buffer Address Case (Slower) */
for (unsigned int secNum = 0; secNum < count && Status == SD_OK; secNum++){
memcpy(dmabuf, buff+SECTOR_SIZE*secNum, SECTOR_SIZE);
Status = SD_WriteBlock(dmabuf,
(uint64_t)(sector+secNum)*SECTOR_SIZE,
SECTOR_SIZE);
}
} else {
/* Aligned Buffer Address Case (Faster) */
if(count==1){
Status = SD_WriteBlock((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE);
}
else{
Status = SD_WriteMultiBlocks((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE
,count);
}
}
#else /* Polling mode */
if(count==1){
Status = SD_WriteBlock((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE);
}
else{
Status = SD_WriteMultiBlocks((uint8_t*)(buff),
((uint64_t)(sector)*SECTOR_SIZE),
SECTOR_SIZE
,count);
}
#endif
if (Status == SD_OK) return RES_OK;
else return RES_ERROR;
}f_writeから渡されるbuffのアドレスの下位2ビットを比較して4Byteの境界に
ない物は整列された配列にコピーし直しシングルブロック転送を行うものです。
このアライメント補正したシングルブロック転送を行っていくとブロックサイズ
の境界(512Byte=128*4Byte)に揃い改めて高速なマルチブロック転送が可能と
なるので効率をなるべく落とさないような仕組みにしてあります。
勿論Readの際もチマチマ読み込みの際は同じような対策でズレを防止できます。
これの対策の元ネタはSTマイクロのフォーラムにあったやり取りです。
かれこれ3年以上経ってましたがねむいさんずっと勘違いしてたせいでこの
対策の意味が今更分かったorzそれにしてもClive1...貴方は何者なんだ…!
そしてChaNさんのページでもズレるから各自対策してね★ってしっかりと
注意書きがしてありました…orz見落としてただけジャン私orz
で、でも現行のSTM32F4Cubeとかのサンプルって1.4.0になってもアライメントの事ガン無視
ですし、ま、まぁこれに気づく人のほうがたぶんす、少ないですってハハ♥
・・・と言うわけでおきぱにあるSTM32F2/F4のサンプルは上記の根本対策を
講じております。好みに合わせてDMAの設定だけで逃げるお手軽対策も
できるようにしてあります。
またF1系,LPC1788/LPC4088のFatFsでも根本対策を施していますので
ご利用ください。ちなみにLPC2388に関してはChaNさん謹製のMCIドライバを
使用していますがちゃんとアラインド/アンアラインド化をしているため
もともと大丈夫です。
●そういえばFatFsの設定で・・・
FatFsの設定のためのffconf.hには_WORD_ACCESSなる定義があり、1にすると
ポインタの参照が32bit単位になり高速化ができる・・・はずですが32bitマイコンの
場合はCPUコアのアライメントの制約で1にすると上で述べたDMAみたく
CPU例外が起こってしまいます。
しかしながらCortex-M3/M4ではアンアラインドなアクセスが一部の命令で可能なため
1にする事ができます。"一部"なのでChaNさんは0を推奨しています。
ねむいさんが試したところではff.cではまだDWORD(8Byte)やそれ以上の
マルチバイトにアクセスする状況が発生していないのでアンアラインド転送の
制約に引っかかるSTRD,STM,LDRD,LDMの命令は現状のコンパイラではff.c内
では一切使用されず例外も発生しないので1で問題はないと言い切れます!
もちろんアンアラインドなアクセスではペナルティが発生してその時の速度は
低下しますがそれでも全体的にはバイトアクセスの時より速度もコードサイズ
でも優れているので積極的に1にしていきましょう!
さらにGCCのコンパイラ・オプションで”-munaligned-access"を有効にすると
アンアラインドアクセスを承知でコードの効率化が図れます。
20160620追:
FatFs0.12ではこのオプションは廃止されました。
コンパイル時に必ずアラインド状態のアクセスになるようコードが変わっています。
20160620追:
ちなみにアンアラインドなアクセスが起こった事を知るための機能もあります。
SCB->CCR |= SCB_CCR_UNALIGN_TRP_Msk;SCBのCCRレジスタにはアンアラインドなアクセスの発生をトラップするビットが
あります。これを立てるとアンアラインド転送が起こった時にHardFaultに
させることができます。
一方Cortex-M0,M0+ではコアのアーキテクチャが違うのでアンアラインドな
データアクセスは許されず、問答無用でHardFaultになりますので常にバイト
アクセスかもしくはアライメントがそろった転送をしましょう。
そういうわけで不具合もしっかりと修正されたので今度こそ実際に
パフォーマンス比較をやっていきたいと思います!
![]()



免責・連絡先は↑のリンクを
↓SNSもやってます↓


 powered by まめわざ
powered by まめわざ
- ARM/STM32 (119)
- OpenOCD (27)
- ARM/NxP (34)
- ARM/Cypress (5)
- ARM/Others (3)
- ARM/Raspi (1)
- AVR (13)
- FPGA (4)
- GPS/GNSS (20)
- MISC (87)
- SDCard_Rumors (2)
- STM8 (2)
- Wirelessなアレ (16)
- おきぱ (1)
- ぱそこんの大先生 (2)
- ブラウザベンチマーク (31)
- 日本の自然歩道 (28)

- SDカードとかUSBメモリにSystem Volume Information絶対作らせなくする方法Win11版
⇒ ねむい (01/28) - SDカードとかUSBメモリにSystem Volume Information絶対作らせなくする方法Win11版
⇒ (01/28) - SDカードとかUSBメモリにSystem Volume Information絶対作らせなくする方法Win11版
⇒ (01/28) - マイコンでSDカード使うときは必ずプルアップしてね☆
⇒ ねむい (11/24) - マイコンでSDカード使うときは必ずプルアップしてね☆
⇒ ひかわ (11/24) - マイコンでSDカード使うときは必ずプルアップしてね☆
⇒ ひかわ (11/24) - マイコンでSDカード使うときは必ずプルアップしてね☆
⇒ ひかわ (11/24) - GNSSモジュールを試用する21 -SAM-M10Qが壊れた…!?と思ったら直せた(おまけあり)-
⇒ Kenji Arai (05/29) - GNSSモジュールを試用する21 -SAM-M10Qが壊れた…!?と思ったら直せた(おまけあり)-
⇒ ねむい (05/26) - GNSSモジュールを試用する21 -SAM-M10Qが壊れた…!?と思ったら直せた(おまけあり)-
⇒ Kenji Arai (05/24)

- February 2026 (1)
- January 2026 (1)
- December 2025 (4)
- November 2025 (1)
- October 2025 (1)
- September 2025 (1)
- August 2025 (1)
- July 2025 (1)
- June 2025 (1)
- May 2025 (1)
- April 2025 (1)
- March 2025 (1)
- February 2025 (1)
- January 2025 (1)
- December 2024 (2)
- November 2024 (1)
- October 2024 (1)
- September 2024 (1)
- August 2024 (1)
- July 2024 (1)
- June 2024 (1)
- May 2024 (1)
- April 2024 (1)
- March 2024 (1)
- February 2024 (2)
- January 2024 (1)
- December 2023 (4)
- November 2023 (2)
- October 2023 (2)
- September 2023 (1)
- August 2023 (2)
- July 2023 (1)
- June 2023 (2)
- May 2023 (3)
- April 2023 (1)
- March 2023 (1)
- February 2023 (1)
- January 2023 (1)
- December 2022 (2)
- November 2022 (1)
- October 2022 (1)
- September 2022 (1)
- August 2022 (1)
- July 2022 (1)
- June 2022 (1)
- May 2022 (1)
- April 2022 (1)
- March 2022 (1)
- February 2022 (1)
- January 2022 (1)
- December 2021 (2)
- November 2021 (2)
- October 2021 (1)
- September 2021 (1)
- August 2021 (1)
- July 2021 (1)
- June 2021 (1)
- May 2021 (1)
- April 2021 (1)
- March 2021 (1)
- February 2021 (1)
- January 2021 (1)
- December 2020 (3)
- November 2020 (1)
- October 2020 (1)
- September 2020 (1)
- August 2020 (1)
- July 2020 (1)
- June 2020 (2)
- May 2020 (1)
- April 2020 (1)
- March 2020 (1)
- February 2020 (1)
- January 2020 (1)
- December 2019 (3)
- November 2019 (1)
- October 2019 (1)
- September 2019 (2)
- August 2019 (1)
- July 2019 (1)
- June 2019 (1)
- May 2019 (1)
- April 2019 (1)
- March 2019 (1)
- February 2019 (1)
- January 2019 (1)
- December 2018 (3)
- November 2018 (2)
- October 2018 (1)
- September 2018 (1)
- August 2018 (1)
- July 2018 (1)
- June 2018 (1)
- May 2018 (1)
- April 2018 (2)
- March 2018 (1)
- February 2018 (1)
- January 2018 (1)
- December 2017 (2)
- November 2017 (2)
- October 2017 (1)
- September 2017 (1)
- August 2017 (1)
- July 2017 (1)
- June 2017 (1)
- May 2017 (1)
- April 2017 (1)
- March 2017 (2)
- February 2017 (2)
- January 2017 (2)
- December 2016 (7)
- November 2016 (2)
- October 2016 (2)
- September 2016 (1)
- August 2016 (1)
- July 2016 (1)
- June 2016 (1)
- May 2016 (2)
- April 2016 (1)
- March 2016 (2)
- February 2016 (1)
- January 2016 (1)
- December 2015 (3)
- November 2015 (1)
- October 2015 (3)
- September 2015 (2)
- August 2015 (2)
- July 2015 (3)
- June 2015 (3)
- May 2015 (4)
- April 2015 (2)
- March 2015 (4)
- February 2015 (1)
- January 2015 (3)
- December 2014 (3)
- November 2014 (2)
- October 2014 (1)
- September 2014 (2)
- August 2014 (2)
- July 2014 (3)
- June 2014 (2)
- May 2014 (1)
- April 2014 (1)
- March 2014 (4)
- February 2014 (4)
- January 2014 (3)
- December 2013 (5)
- November 2013 (4)
- October 2013 (3)
- September 2013 (2)
- August 2013 (2)
- July 2013 (2)
- June 2013 (3)
- May 2013 (2)
- April 2013 (2)
- March 2013 (2)
- February 2013 (2)
- January 2013 (3)
- December 2012 (4)
- November 2012 (2)
- October 2012 (2)
- September 2012 (4)
- August 2012 (1)
- July 2012 (3)
- June 2012 (2)
- May 2012 (3)
- April 2012 (3)
- March 2012 (2)
- February 2012 (3)
- January 2012 (3)
- December 2011 (5)
- November 2011 (3)
- October 2011 (2)
- September 2011 (2)
- August 2011 (2)
- July 2011 (2)
- June 2011 (2)
- May 2011 (2)
- April 2011 (2)
- March 2011 (2)
- February 2011 (2)
- January 2011 (3)
- December 2010 (7)
- November 2010 (1)
- October 2010 (1)
- September 2010 (1)
- August 2010 (3)
- July 2010 (4)
- May 2010 (1)
- April 2010 (2)
- March 2010 (2)
- February 2010 (2)
- January 2010 (3)
- December 2009 (3)
- November 2009 (8)
- October 2009 (7)
- September 2009 (5)
- August 2009 (4)
- July 2009 (6)
- June 2009 (6)
- May 2009 (14)
- January 1970 (1)


Copyright(C) B-Blog project All rights reserved.
Comments
Post a Comment